Paper - AdderNet: Do We Really Need Multiplications in Deep Learning?
Review Note
1 Introduction
Origin:
- CVPR 2020 Oral
Author:
- Peking University
- Huawei
- The University of Sydney
Task:
- Energy efficient networks
Existing Methods:
- Network pruning
- Efficient blocks design (e.g. MobileNet, ShuffleNet)
- Knowledge Distillation
- Low-bit Quantization (e.g. Binary Neural Network)
Limitations:
- Containing massive multiplications
Proposed Method:
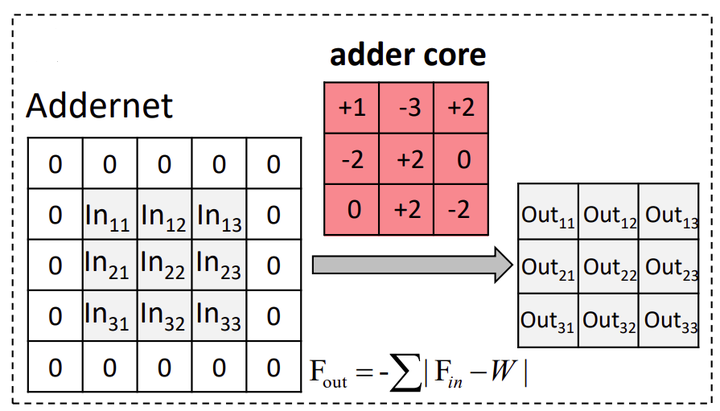
Today’s convolution operation of convolution neural network (CNN) includes a lot of multiplication. Although there are many lightweight networks (such as MobileNet) proposed, the cost of multiplication is still hard to be ignored. To carry out deep learning application in edge devices, it is necessary to further lower the computation cost and energy consumption, so this paper proposes to use addition operation instead of multiplication operation to perform deep neural networks.
The paper points out that the traditional convolution operation is actually a kind of cross-correlation operation used to measure the similarity between input features and convolution kernels, and this cross-correlation operation introduces many multiplication operations which increase the computation cost and energy consumption, so the paper proposes another way to measure the similarity between input features and convolution kernels, which is
2 Method
2.1 Similarity Measurment
Suppose that
where
2.2 Convolution Kernel
If
2.3 Addition Kernel
As mentioned above, if
here the author mentioned that the results of such operations are all negative, but the output value of the traditional convolutional neural network is positive or negative, therefore, behind the output layer is the Batch Normalization (BN) layer, which makes the output distribution in a reasonable range.
2.4 Optimization
In traditional convolution networks, the back propagation formula of
The derivative of
In AdderNet, the back propagation formula of
It is pointed out in the paper that the signSGD of
The derivative of
In AdderNet, the back propagation formula of
Considering the derivative of
2.5 Adaptive learning rate
In traditional CNN, normally we expect that the output distribution between each layer is similar, so that the weights of the network are more stable. Considering the variance of the output features, we assume that all values in
Similally, the variance in AdderNet has the following formula:
The variance of CNN is small because
In AdderNet, the output of each layer is followed by a BN layer. Although BN layer brings some multiplication operations, the magnitude of these operations can be ignored compared with that of classical convolution network. Given a mini-batch input
where
Then the partial derivation of
Since the weight gradient depends on the variance, the weight gradient in the AdderNet with BN layer will be very small. The following table is a comparison:

Except for showing a small gradient, the table also shows that some layers may not be of the same magnitude, so it is no longer appropriate to use a global unified learning rate. Therefore, an adaptive learning rate method is used in the paper, making the learning rate different in each layer. Its formula calculation is expressed as:
where
where
With such a learning rate adjustment, the learning rate can be automatically adapted to the situation of the current layer in each layer.
2.6 Training Procedure
The above is all the new ideas and designs proposed in this paper, and the process description of forward and backward propagation of AdderNet is also given in this paper as below.

3 Experiment
See the original paper for the comparison of experimental data and results.
Thinking
When I first read this paper, I thought it was another version of the Binary Neural Network, but after reading it carefully, I found that it was actually a new form of reducing the FLOP. The amount of calculation is a compromise between quantization calculation and full-precision calculation, with a comparable accuracy compared to the traditional CNNs. The storage amount would be larger than quantified CNNs. I think if we can combine other methods (such as quantization, pruning) and other algorithms, there will be more new ideas. It is a direction worth to study.